Per #rispondosuquora oggi rispondo alla domanda “come ritrovare pagine web che non esistono più?”.
Il modo migliore per ritrovare pagine web che non esistono più è sicuramente utilizzando la Wayback Machine di archive.org.
Archive.org è un progetto open source (il codice sorgente della wayback machine è disponibile gratuitamente online). È dal 1996 che questo servizio sta archiviando i contenuti del web, giorno dopo giorno, creando così un grande database della storia del web.
All’interno del suo archivio, a fine Ottobre 2019 sono presenti oltre 387 miliardi di pagine web, che descrivono l’evoluzione di milioni di siti web.
Ad esempio, per il solo sito di repubblica.it sono disponibili 31.520 registrazioni, comprese tra il 13 Novembre 1996 ed il 26 Ottobre 2019 (questo articolo lo sto scrivendo il 27 Ottobre, quindi fino a ieri).
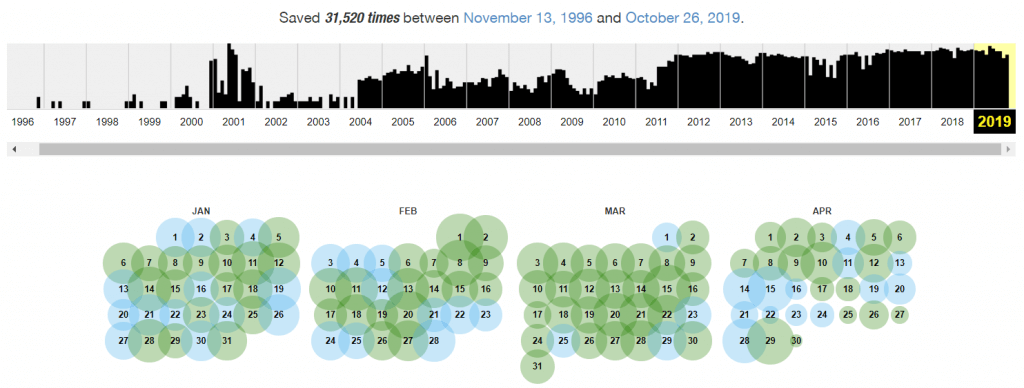
Ed una “registrazione” non è una singola pagina, ma per i siti più complessi ed importanti, viene effettuata una copia di più pagine.
Ad esempio, ecco la home page di Repubblica il 29 febbraio del 2000
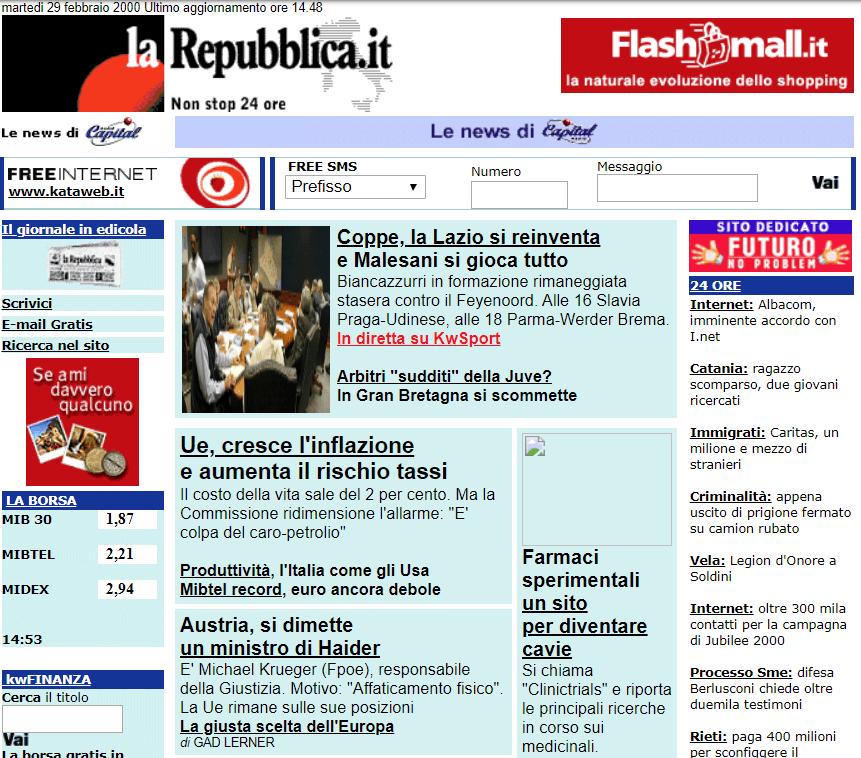
Ed un articolo di una pagina interna
Tutto questo è possible grazie al sito Internet Archive (https://archive.org).
Oltre a rispondere alla domanda “come ritrovare una pagina web”, Internet Archive ha anche un archivio di testi, video, software, immagini ed altro ancora

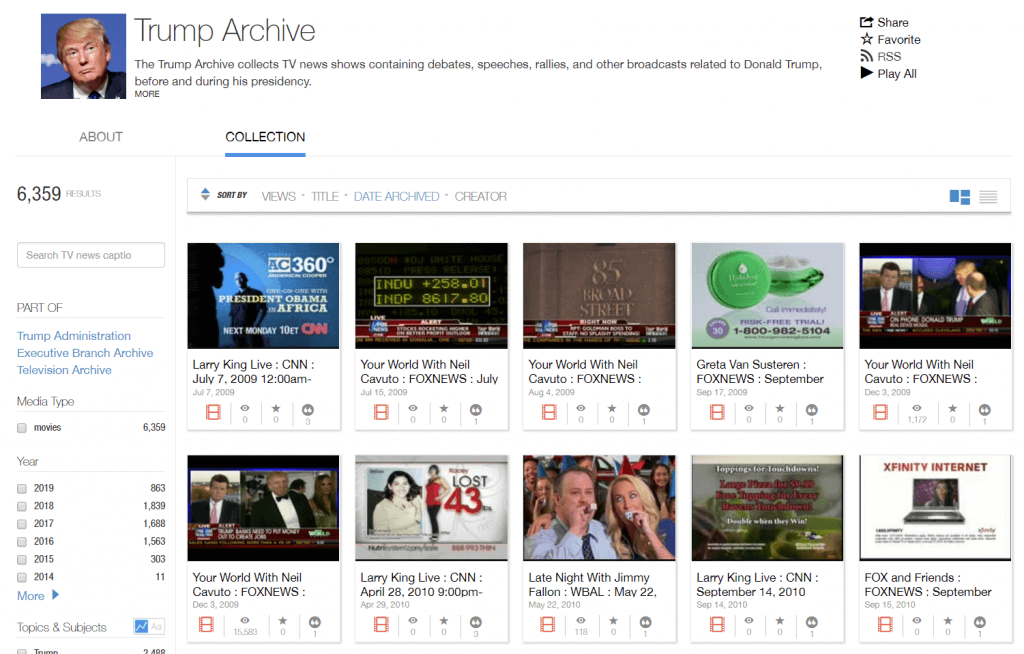
Per ogni categoria, sono poi disponibili delle collezioni. Dei raggruppamenti di contenuti per uno specifico tema. Ad esempio, sotto la categoria TV è presente una collezione dedicata a Trump.
Il motore che permette a tutto questo di funzionare è il crawler di Alexa (di proprietà di Amazon), che si occupa di analizzare i vari siti e di memorizzarne delle copie.
Inoltre, ogni utente può anche richiedere di salvare il proprio sito web, al fine di essere certi di garantire una copia anche dei propri siti.
Da notare che questo non è un passaggio necessario. Il crawler di Alexa potrebbe aver trovato il vostro sito ed averne creato una copia, anche senza la vostra segnalazione (così come è avvenuto ad esempio per il mio sito).
Seguimi su Quora: https://it.quora.com/profile/Omar-Venturi#
https://it.quora.com/Come-ritrovare-pagine-WEB-che-non-esistono-pi%C3%B9/answer/Omar-Venturi
